
A core piece of Aurora’s technology is the Aurora Engine smart contract, which is an Ethereum Virtual Machine (EVM) implementation deployed as a smart contract on Near. Therefore, Aurora sits at the intersection of both EVM and Near runtimes. It naturally draws us to think about comparisons between EVM and Near.
For example, the concept of “gas” exists in both the EVM and Near’s runtime. The reason is because of the famous halting problem, which says we cannot know in advance if an arbitrary computer program will finish in a finite time. In the context of a smart contract platform, this means we must measure (and limit) the computation the contract does at runtime. In both the EVM and Near, “gas” is the unit that is used to measure the computational work done by a smart contract.
Even though EVM gas and Near gas both measure the same thing, they are not identical. One analogy is miles and kilometers; both measure distance, but the numerical value of the same physical distance will be different depending on which unit is used. Computation is a more abstract concept than distance, but this analogy leads us to expect some kind of approximately linear relationship between EVM gas and Near gas, similar to how 1 mile equals 1.61 kilometers.
In this blog post, we explore this question and discuss the implications for developers building on Aurora.
The theoretical relation
In theory, we should be able to derive the relationship between EVM gas and Near gas by considering the EVM gas cost of each operation in the EVM and calculating how much Near gas this same operation costs based on its implementation in Aurora. Unfortunately, this is much more difficult in practice than it sounds. The Aurora Engine is written in Rust and compiled to Web Assembly (Wasm). This compilation process convolutes the conceptual mapping between EVM opcodes and operations in the Near runtime. There are additional complexities in trying to do this calculation in that Aurora virtualizes the whole EVM inside Wasm, and hence how much Near gas an opcode takes may depend on the overall VM state (e.g., because more Wasm memory needs to be allocated).
While it is good to have this idea of being able to calculate the relationship from first principles (and we will revisit it later in this post), it is not a practical way to answer our question. For that, we will use empirical data instead.
Gathering data
Data for EVM and Near gas used for all transactions on Aurora is available via a combination of our RPC and Near’s RPC. Consider the following call (done via the command line using the HTTPie tool):
http post https://mainnet.aurora.dev/ jsonrpc=2.0 id=1 \
method=eth_getTransactionReceipt \
params:='["0x4c2b8b5d766fe0411d0003bf4c9d2becc9d6dd7120272cf9f1a6cac73e4c3543"]'The parameter in this call can be any hash of a transaction on Aurora (the given one is only an example). Notice the gasUsed field in the response, which gives the (hexadecimal encoded) amount of EVM gas used in the transaction (46,574 in this example).
In addition to the standard response fields defined by the Ethereum standard, the Aurora RPC returns two other fields: `nearReceiptHash` and `nearTransactionHash`. These give the receipt/transaction hashes corresponding to the underlying transaction that was executed on Near (by the Aurora Engine contract).
To use these extra fields, there is some additional work involved because Near hashes are always presented in base58 encoding, whereas our RPC returns them in hexadecimal encoding (to be consistent with how Ethereum usually presents hashes). You can read more about this in a previous article. For our purposes here, it is easy enough to write a Python script to do the conversion for us and chain this together with the jq tool to get the Near transaction hash in one command:
http post https://mainnet.aurora.dev/ jsonrpc=2.0 id=1 \
method=eth_getTransactionReceipt \
params:='["0x4c2b8b5d766fe0411d0003bf4c9d2becc9d6dd7120272cf9f1a6cac73e4c3543"]' \
| jq .result.nearTransactionHash | hex2b58From the Near transaction hash, we can get the amount of Near gas used in the transaction from the Near RPC:
http post https://archival-rpc.mainnet.near.org jsonrpc=2.0 id=dontcare \
method=tx \
params:='[ "46ACGRcUQadezAWQuZ9WVopSAbeeWpJZ1H8hmVuWPhJu", "relay.aurora"]'Where the first parameter is the Near transaction hash obtained from the Aurora RPC by the previous command. There is a lot of data returned from the response, but for our purposes, we only care about the gas used in the Aurora Engine execution. We can isolate just this part of the response using jq:
http post https://archival-rpc.mainnet.near.org jsonrpc=2.0 id=dontcare \
method=tx \
params:='[ "46ACGRcUQadezAWQuZ9WVopSAbeeWpJZ1H8hmVuWPhJu", "relay.aurora"]' \
| jq '.result.receipts_outcome[0].outcome.gas_burnt'Given this, it’s pretty easy to automate obtaining the EVM and Near gas data from any Aurora transactions we want!
Empirical results
In what follows, we consider all the successful (i.e., ignoring obvious failures like incorrect nonce – these would be outliers in our data because they don’t do any real EVM execution) Aurora transactions from June 4, 2023 (block height 93442283) to June 12, 2023 (block height 94047083). Below is a plot of EVM gas vs Near gas. The Near numbers have been scaled by 10^12 since Tgas is the common unit Near gas values are presented in, and the EVM numbers have been scaled by 10^3 since the smallest EVM gas possible is 2100.

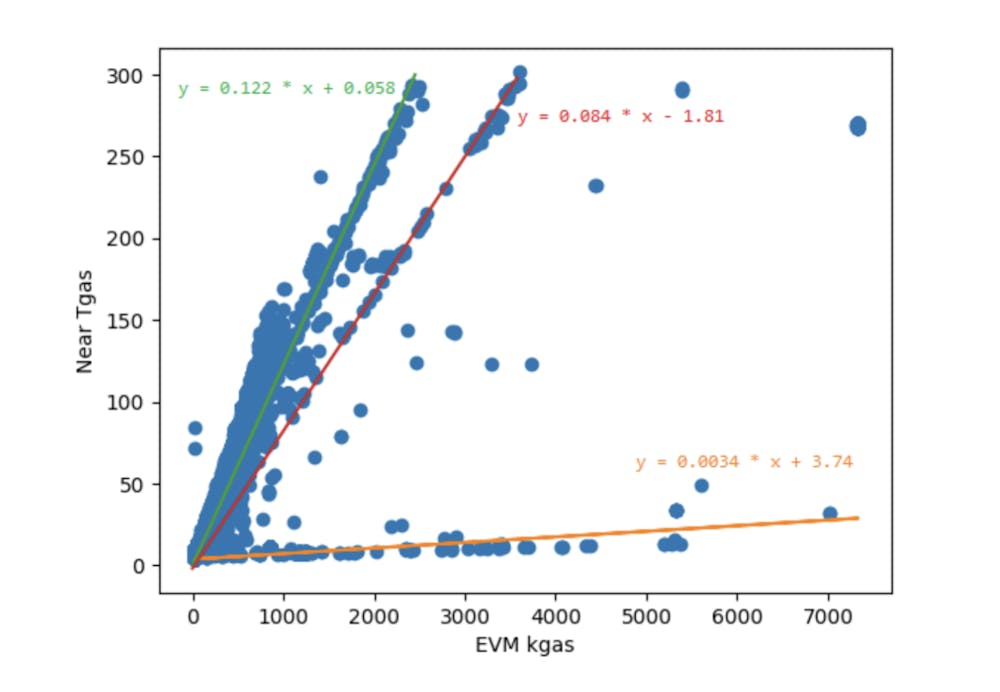
As expected, there is a strong linear correlation between the values. Though interestingly, there are (at least) 3 distinct lines as opposed to just one.
The line with the shallowest slope (orange line in the plot) corresponds to storage-heavy transactions (e.g., contract deployments). These transactions use a lot of EVM gas but not very much Near gas. The reason is because of the difference in how the EVM charges for storage and how Near charges for it. In the EVM, storage access is pretty expensive in terms of gas, but there is a gas refund when storage is released. On the other hand, Near does not change much gas for storage access but does charge the account in the form of storage staking (the account must maintain a minimum Near balance to be allowed to have so much storage used). This difference in how storage is charged means disproportionately less Near gas is used for storage compared to other computational costs (e.g., CPU and memory access).
The majority of points in the plot lie on the steepest line (green line in the plot), though there is a lot of variance around it. Taking a linear regression of this data, we determine the average slope is around 0.122. This provides us an empirical answer to our question of how EVM and Near gas are related on Near. Approximately 1.22 x10^8 Near gas is spent per EVM gas. In fact, this relation is what informs the fixed EVM gas price set by Aurora’s relayers. The relationship between EVM gas and Near gas allows us to convert Near’s gas price into an EVM gas price to charge our users (of course, most users take advantage of the free transaction available from AuroraPass and don’t worry about gas prices anyway).
The red line in the plot follows a distinct collection of points between the “storage-heavy” and “main” lines. I do not know what is special about these transactions, which makes them use less Near gas than those on the main trendline. It is difficult to learn high-level information about transactions just from the set of addresses they call and the binary input they send. One hypothesis could be that these transactions are literally a middle-ground between the two extremes of the gas, primarily coming from CPU costs and primarily coming from storage costs. There could be something about the algorithm the smart contracts implement such that the amount of storage access they need is proportional to the amount of CPU-bound computation they perform. Regardless of the reason, this may be useful information for the developers of those contracts to know since they are able to complete transactions with higher EVM gas values than transactions on the main line.
This data has additional consequences for developers on Aurora. For example, our documentation mentions an edge case incompatibility between Aurora and Ethereum mainnet where a transaction may run out of Near gas before it runs out of EVM gas. This causes the transaction to fail on Aurora when it would pass on Ethereum. The transaction gas limit on Near (no such concept exists on Ethereum, there is only the block gas limit) is 300 Tgas, which implies that this edge case described in the documentation arises for EVM transactions exceeding approximately 2.5 x 10^6 EVM gas. This assumes the transaction lies on the main trendline, though, as we discussed, there are other kinds of transactions with different Near/EVM gas conversion ratios that can achieve higher EVM gas values.
Future directions
For us internally at Aurora, this plot also gives us a clear metric for our Engine’s performance. Our goal is to process EVM transactions as efficiently as possible (i.e., use as little Near gas as possible per EVM gas), which corresponds to lowering the slope of the main trendline in the EVM gas vs. Near gas plot. Since Aurora launched, we have made a lot of progress in this respect: more than a factor of 2 improvement since February 2022 (Engine v2.4.0 vs. v2.9.0). But we still have more work to do. We would like to make the amount of EVM gas that fits into 300 Near Tgas equal to the Ethereum block gas limit (30 x 10^6 EVM gas) so that our developers no longer need to worry about the edge case discussed above. Because, in this case, we will be sure that no EVM transaction which succeeds on the Ethereum mainnet can exceed 300TGas on Near. Going back to the theoretical argument from earlier in the article, we know that we should be able to improve the Engine’s efficiency by changing the implementation details. In particular, the overhead of running an EVM interpreter must contribute to the Near gas cost significantly.
Our next innovation towards this goal is to develop an EVM to Wasm compiler. Such a compiler will allow directly executing EVM contracts in the Near runtime instead of needing to interpret them within a virtualized EVM. Some simple benchmarking data suggests that we should be able to get orders of magnitude performance improvements using this kind of approach.